
AI in Regulatory Submissions: Writing for Both Human and Machine Reviewers

This week in the Guardrail, we analyze the dual-audience reality facing modern pharmaceutical compliance. As regulatory agencies integrate automated tools to parse complex submissions, drug sponsors must adapt their documentation strategies to satisfy both algorithmic logic and human expertise.
By Michael Bronfman
May 25, 2026
The world of making and approving medicines is going through a massive shift. For decades, pharmaceutical companies wrote drug applications for just one audience: human scientists. Teams of medical doctors, chemists, and statisticians at agencies like the Food and Drug Administration would read thousands of pages of text to decide if a new drug was safe.
Today, that process looks very different. Pharmaceutical companies now use computer algorithms, known as Artificial Intelligence, to run clinical trials and analyze data. At the same time, the regulatory agencies themselves are starting to use computer programs to help read and sort through massive piles of application documents.
This means medical writers and drug sponsors must now write for two very different audiences at the same time. They must write for the human experts who make the final decisions, and they must write for the machine reviewers who scan the text for errors and patterns. If an application is not structured correctly for a machine to read, it could get flagged for inconsistencies before a human expert even looks at it.
To help companies navigate this change, the Food and Drug Administration released official draft guidance about using these advanced computer models in drug development. This document outlines exactly how the agency looks at data generated by computers and how companies should share that information. For more detailed context, you can read the official announcement on the FDA Press Release Page.
The Food and Drug Administration Risk Framework
The official policy from the government makes one thing very clear: not all computer applications are treated equally. The agency uses a risk-based framework to grade how much scrutiny a system needs. This framework is based on two main ideas: model influence and decision consequence.
Model influence means how much the computer output affects the final decision. If a computer makes a final choice on its own, its influence is strong. If a human expert checks the work and can override the computer, its influence is lower. Decision consequence means what could go wrong if the computer makes a mistake. If a computer error harms a patient, the consequences are high. If an error just slows down a factory machine for an hour, the consequence is low.
By looking at these two factors, the government separates computer tools into high-scrutiny systems and low-requirement systems.

High Scrutiny Systems
The highest level of official review is saved for computer systems that directly create evidence for a drug application. These are systems where a mistake could directly hurt a patient or ruin the results of a scientific study.
The government pays closest attention to these five specific areas:
Patient Stratification: Choosing which patients get to be in a clinical trial based on their genetic codes or medical histories.
Dose Optimization: Using mathematical models to calculate exactly how much medicine a patient should take to get better without getting sick from side effects.
Real World Data Analysis: Scanning millions of electronic health records from hospitals to see how a drug performs in everyday life outside of a controlled trial.
Safety Signal Detection: Watching patient data in real time to spot rare and dangerous side effects before they become a widespread public health crisis.
Endpoint Derivation: Using wearable sensors like smartwatches to measure how well a patient is moving or sleeping during a clinical trial.
If a company uses a computer for any of these tasks, it must prove the system is incredibly reliable. They must show how the model was trained, what data it used, and how it avoids bias.
Low-Requirement Systems
On the other side of the coin, some computer uses do not impact patient safety at all. If a company uses a computer tool to format a document, check page numbers, or organize internal administrative tasks, the government does not need to see piles of validation data. These internal operations face proportionally lower requirements because a mistake by the computer will not change the scientific conclusions of the drug trial.
Understanding the Double Audience
Because regulatory agencies are now using advanced software to help manage incoming applications, drug sponsors must realize they are writing for a double audience. The text must satisfy both the human brain and the computer algorithm.
To see how these two audiences read differently, look at this comparison:
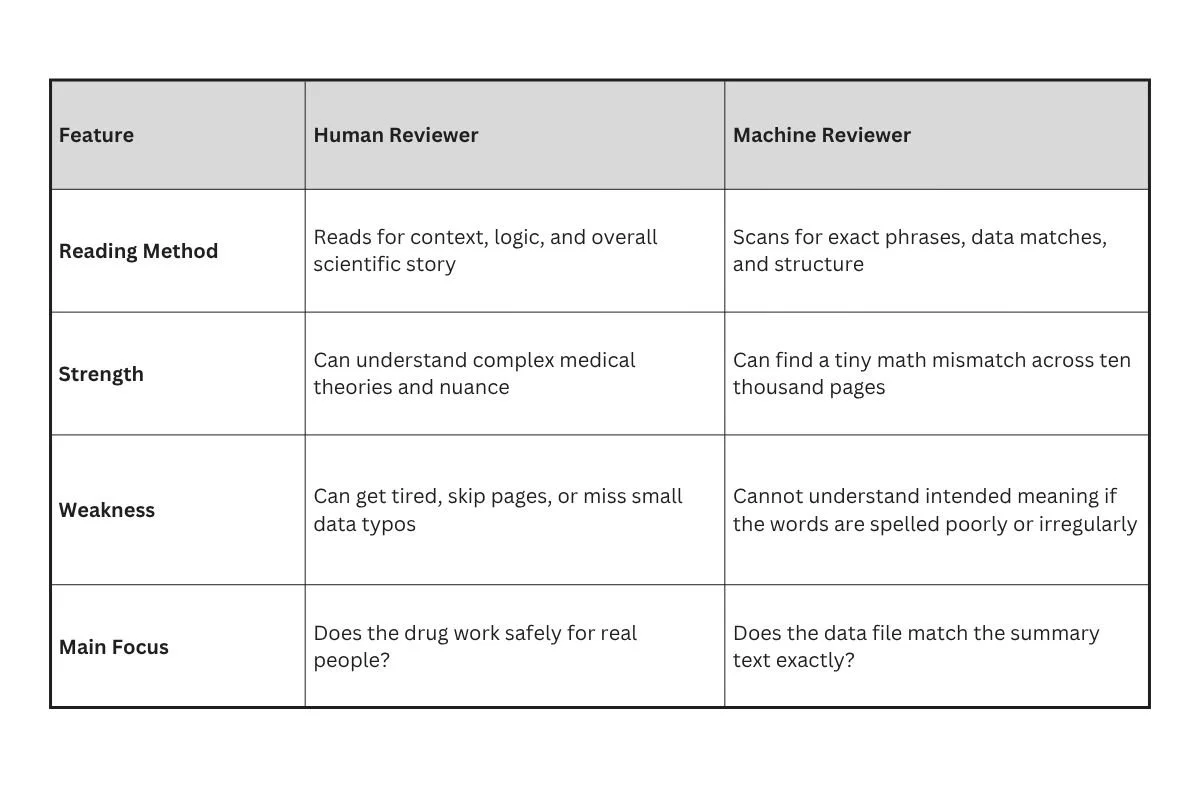
When a human reads a drug application, they want a clear narrative. They want to understand the journey of the drug from the laboratory to the clinic. They care about scientific logic.
A machine reviewer does not care about stories. It treats the document like a database. It looks at the tables, the labels, and the numbers to make sure everything adds up perfectly. If the summary on page five says fifty patients had a headache, but the raw data table on page nine hundred says forty-nine patients had a headache, the machine will flag that instantly. A human might miss that small slip, but a machine never will.
Writing for the Machine Reviewer
Writing for a computer means changing how you present text. Computers like clean organization, predictable patterns, and explicit language. If you write with vague words, the software can get confused and flag your document as a risk.
Structure and Predictability
The best way to help a machine reviewer is to use standard templates. Regulatory documents should follow strict structural rules. Use clear, standardized headings for every section. Do not try to be creative with section titles. If the standard title is Clinical Efficacy, do not change it to How Well the Drug Worked. The computer looks for specific keywords to map the document, and changing those keywords breaks the map.
Data Consistency and Labels
Every data point must look identical throughout the entire file. If you refer to a drug concentration as ten milligrams on one page, do not write it as 10mg on the next page. Choose one format and stick to it.
Also, make sure that every chart and table has clear, descriptive labels that use text instead of scanned images. Machine reviewers read text characters, not picture pixels. If you paste a picture of a table into your document, the computer sees a blank space and misses all the important data inside it.
Front Loading for Clarity
Machines are built to look for core conclusions early. Put your main findings, safety summaries, and essential data points right at the front of your sections. Do not hide your main message under paragraphs of introductory fluff. Front loading your clarity helps the computer categorize your document correctly on its very first pass.
Writing for the Human Reviewer
While you must make your document easy for a computer to analyze, you cannot forget the human being who must sign the final approval paper. Humans need context, clear explanations, and a believable scientific argument.
Explaining the Why
A machine can show that a number changed, but only a human can explain why it changed. If a clinical trial had a sudden drop in patient attendance during month four, a machine might flag it as a data error.
The human writer needs to explain the context:
"Patient attendance dropped in month four due to a historic blizzard that closed three major clinical trial sites for two weeks, but patients resumed their regular visits as soon as the roads cleared."
This explanation satisfies the human reviewer and prevents them from rejecting the data.
Keeping the Story Alive
A good regulatory submission tells a story of safety and success. The human writer must connect the dots between different pieces of research. Show how the animal studies predicted the human results, and show how the human results match the goals of the project. Use active, plain verbs to explain what the scientists did. Avoid overly dense language that puts the reader to sleep. A tired reviewer is a frustrated reviewer.
Conducting an Internal Review
Before you click the submit button to send your drug application to the government, your team should perform a complete internal review. This means testing your document against your own software tools to see what a machine reviewer will find.
Step One: The Automated Consistency Check
Run your completed document through text-matching software. This program should look for every number, percent, and statistical value to make sure they match perfectly across all chapters. If the software finds a conflict, fix it immediately. You want to find these errors yourself rather than letting the government find them first.
Step Two: The Structure Audit
Verify that every hyperlink works and leads to the correct appendix. Check that your document map functions properly and that all headings match the standard table of contents. If a machine cannot navigate your document links, it may automatically reject the file.
Step Three: The Human Readability Pass
Have a scientist who did not write the document read it for flow and clarity. Ask them if the arguments make sense and if the explanations are easy to find. This step ensures that once your document passes the computer gates, it will please the human experts.
The Path Forward for Drug Developers
The use of computer intelligence in regulatory submissions is not a temporary trend. It is the permanent future of medicine. Drug companies that learn how to write for both humans and machines will get their medicines approved much faster. Those who stick to old ways of writing will face constant delays, data flags, and rejection notices.
To keep up with these changes, companies should train their medical writers in basic data science principles. Writers do not need to learn how to code, but they do need to understand how computers read and sort information. By focusing on predictability, exact data matches, and clear summaries, you can create a document that satisfies the cold logic of a machine and the deep wisdom of a human scientist.
To learn more about how the government views these new digital tools, you can review the comprehensive resources provided by theFDA Artificial Intelligence Development Page. Staying informed about these official updates is the best way to ensure your future submissions are successful.